Sensor Analysis Framework¶
![]()
![]()
![]()
When dealing with sensor data, specially with low cost sensors, a great part of the effort needs to be dedicated to data analysis. After a careful data collection, this stage of our experiments is fundamental to extract meaningful conclusions and prepare reports from them. For this reason, we have developed a data analysis framework that we call the Sensor Analysis Framework. In this section, we will detail how this framework is built, how to install it, and make most use of it.

We care for open science¶
The framework is written in Python, and can be easily installed on any computer with simple pip install scdata. It is intended to provide an state-of-the art data analysis environment, adapted for the uses within the Smart Citizen Project, but that can be easily expanded for other use cases. The ultimate purpose of the framework is to allow for reproducible research by providing a set of tools that can be replicable, and expandable among researchers and users alike, contributing to FAIR data principles.

By SangyaPundir - Own work, CC BY-SA 4.0
Raw and processed data
All the raw sensor data from the devices is sent to the Platform and processed outside of the sensors. Raw data is never deleted, and the postprocessing of it can be traced back to it's origin by using the sensor blueprint information. This way, we guarantee openness and accesibility of the data for research purposes.
Check this guide to learn more about how we postprocess the data of the sensors and how to make it your own way.
The framework integrates with the Smart Citizen API and helps with the analysis of large amounts of data in an efficient way. It also integrates functionality to generate reports in html or pdf format, and to publish datasets and documents to Zenodo.
More familiar with R?
R users won't be left stranded. RPY2 provides functionality to send data from python to R quite easily.
How we use it¶
The main purpose of the framework is to make our lives easier when dealing with various sources of data. Let's see different use cases:
Get sensor data and visualise it
This is probably the most common use case: exploring data in a visual way. The framework allows downloading data from the Smart Citizen API or other sources, as well as to load local csv files. Then, different data explorations options are readily available, and not limited to them due to the great visualisation tools in python. Finally, you can generate html, or pdf reports for sharing the results.
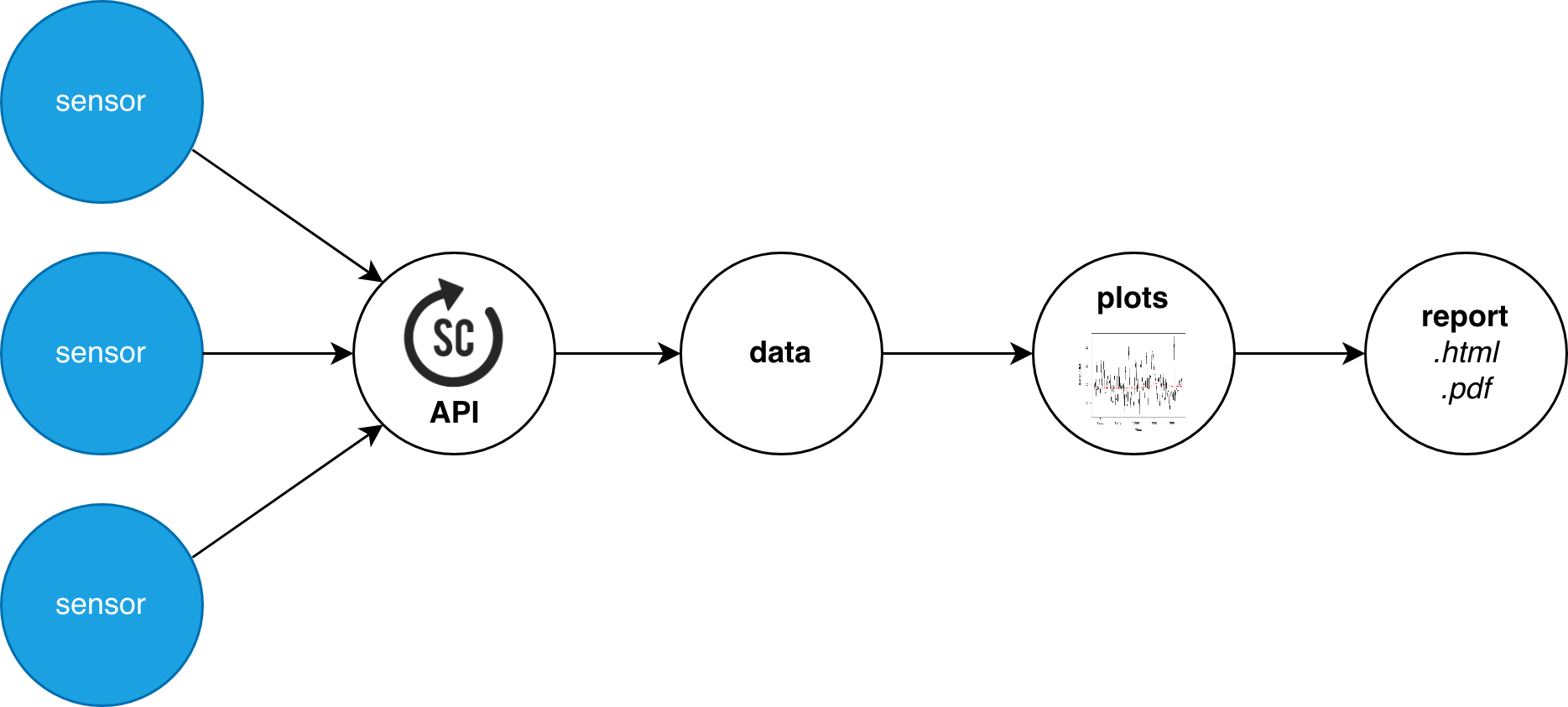
Examples
Check the examples in the Github Repository
Organise your data
Handling a lot of different sensors can be at times difficult to organise and have traceability. For this, we created the concept of test, which groups a set of devices, potentially from various sources. This is convenient since metadata can be addeed to the test instance describing, for instance, what was done, the calibration data for the device, necessary preprocessing for the data, etc. This test can be later loaded in a separate analysis session, modified or expanded, keeping all the data findable.
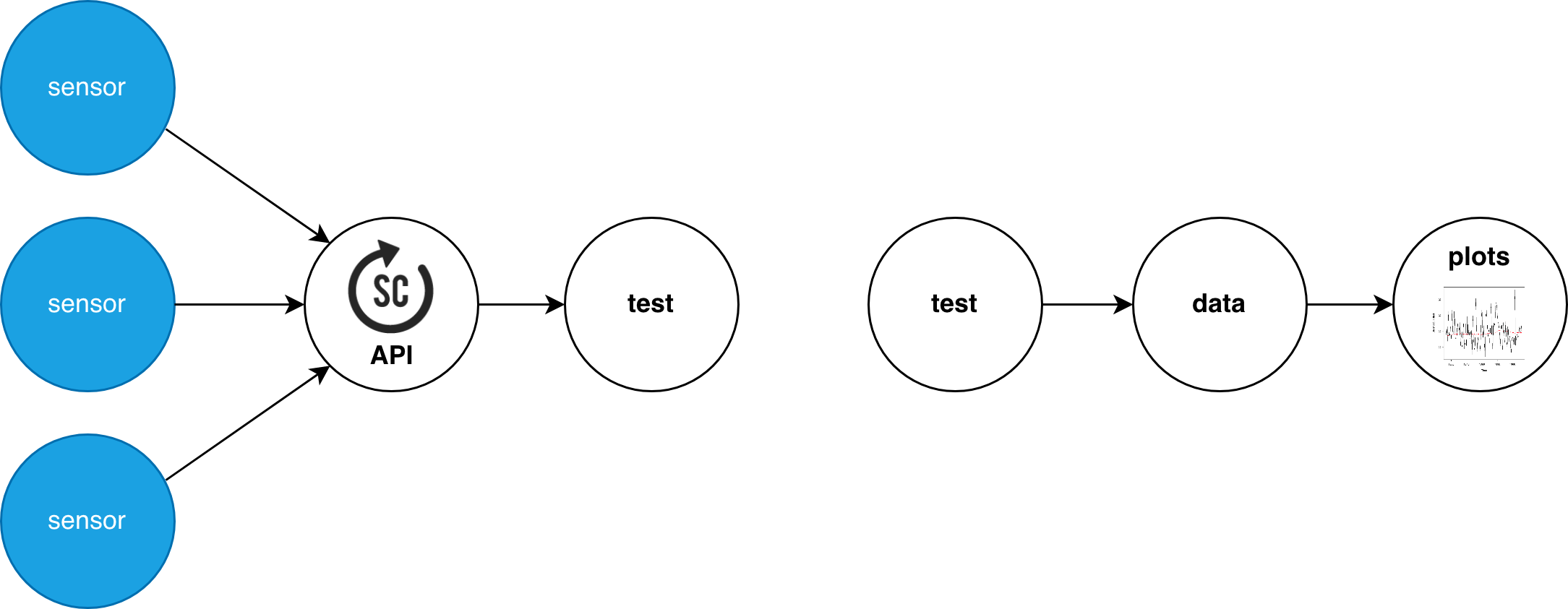
Some example metadata that can be stored would be:
- Test Location, date and author
- Kit type and reference
- Sensor calibration data or reference
- Availability of reference equipment measurement and type
Check the guide
Check the guide on how to organise sensor data
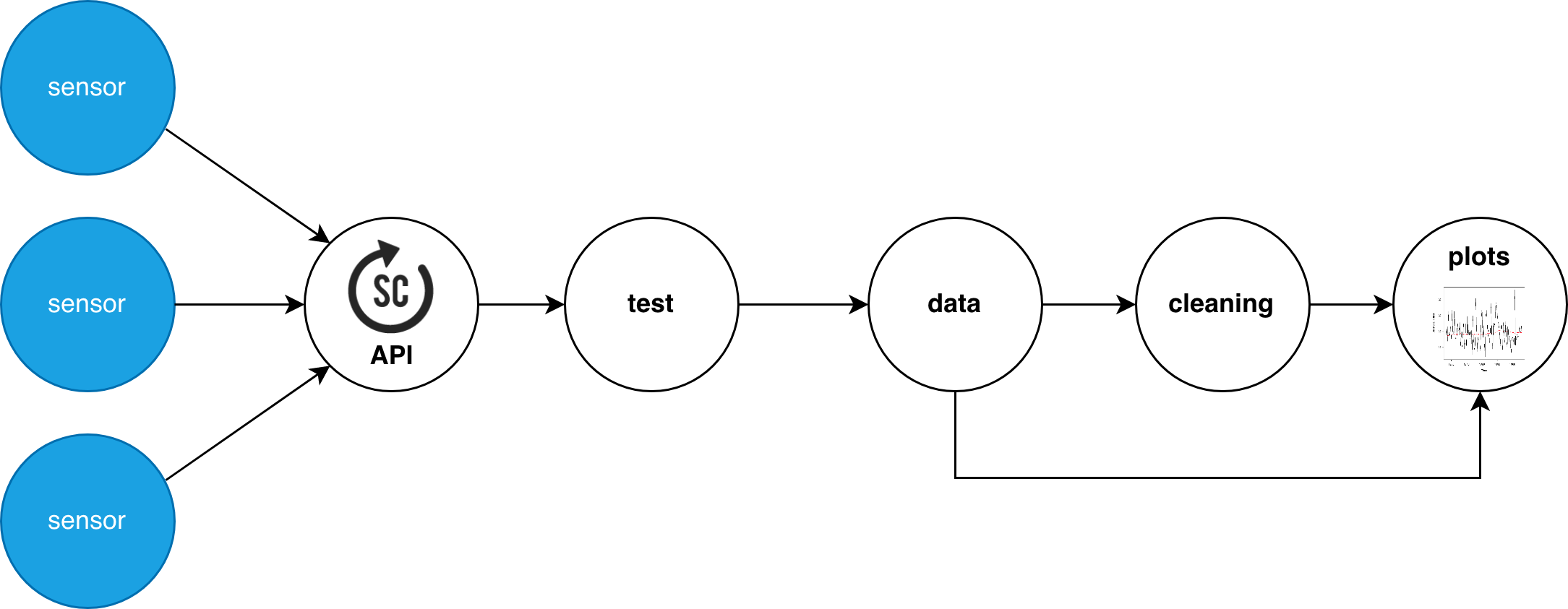
Clean sensor data
Sensor data never comes clean and tidy in the real world. For this reason, data can be cleaned with simple, and not that simple algorithms for later processing. Several functions are already implemented (filtering with convolution, Kalman filters, anomaly detection, ...), and more can be implemented in the source files.
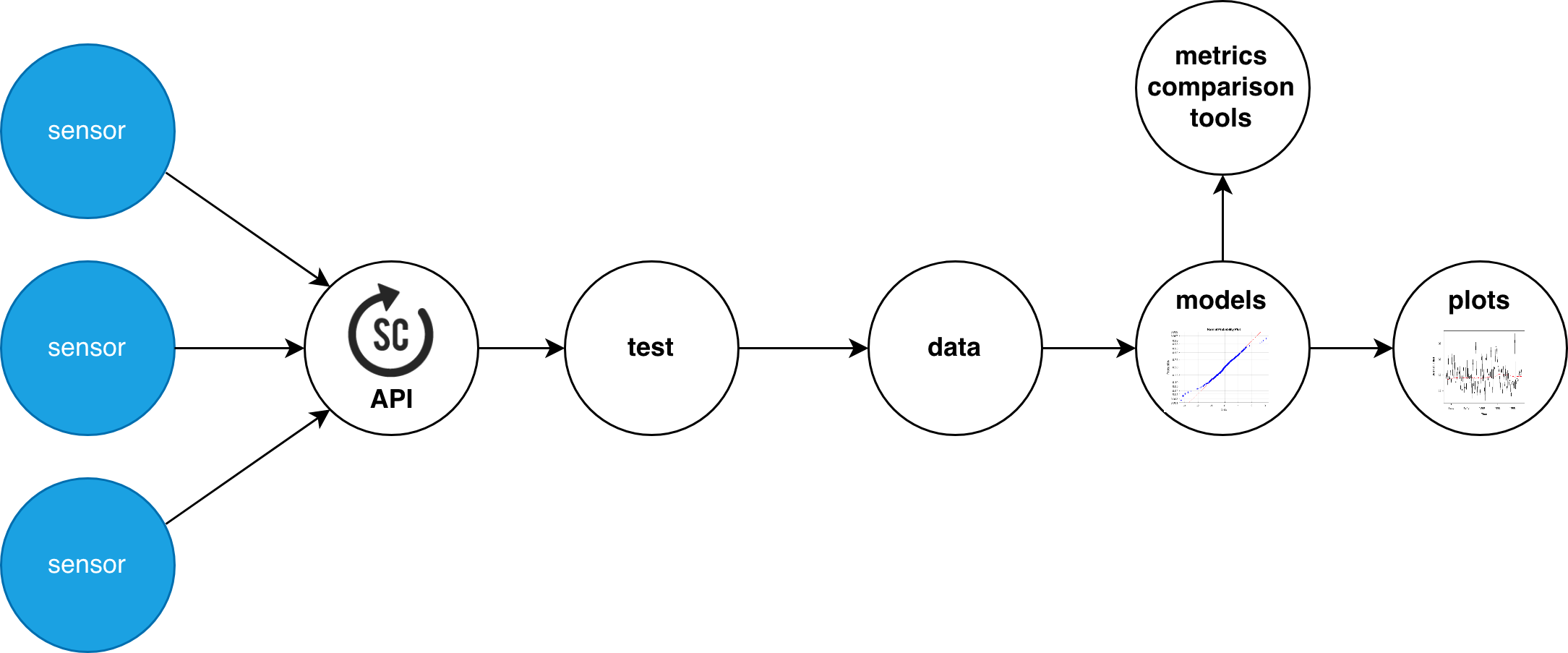
Model sensor data
Low cost sensor data needs calibration, with more or less complex regression algorithms. This can be done at times with a simple linear regression, but it is not the only case. Sensors generally present non-linearities, and linear models might not be the bests at handling the data robustly. For this, a set of models ir rightly implemented, using the power of common statistics and machine learning frameworks such as sci-kit learn, tensorflow, keras, and stats models.
Guidelines on sensor development
Check our guidelines on sensor deployment to see why this is important in some cases.
Batch analysis
Automatisation of all this tools can be very handy at times, since we want to spend less time programming analysis tools than actually doing analysis. Tasks can be programmed in batch to be processed automatically by the framework in an autonomous way. For instance, some interesting use cases of this could be:
- Downloading data from many devices, do something (clean it) and export it to .csv
- Downloading data and generate plots, extract metrics and generate reports for many devices
- Testing calibration models with different hyperparameters, modeling approaches and datasets

Share data
One important aspect of our research is to share the data so that others can work on it, and build on top of our results, validate the conclusions or simply disseminate the work done. For this, integration with zenodo is provided to share datasets and reports:

Have a look at the features within the framework:
- Tools to retrieve data from the Smart Citizen's API or to load them from local sources (in csv format, compatible with the SCK SD card data)
- A data handling framework based on the well known Pandas package
- An exploratory data analysis tools to study sensor behaviour and correlations with different types of plots
- A sensor model calibration toolset with classical statistical methods such as linear regression, ARIMA, SARIMA-X, as well as more modern Machine Learning techniques with the use of LSTM networks, RF (Random Forest), SVR (Support Vector Regression) models for sequential data prediction and forecasting
- Methods to statistically validate and study the performance of these models, export and store them
- As a bonus, an interface to convert the python objects into the statistical analysis language R
Info
Check the guide on how to set it up here