Model your sensor data¶
In this section, we will detail how to develop models for our sensors. We will try two different approaches for model calibration:
- Ordinary Least Squares (OLS): based on the statsmodels package, the model is able to ingest an expression referring to the kit's available data and perform OLS regression over the defined training and test data
- Machine Learning (LSTM): based on the keras package using tensorflow in the backend. This framework can be used to train larger collections of data, among others:
- Robust to noise
- Learn non-linear relationships
- Aware of temporal dependence
Load some data first
We will need to load the data first, for this, check the guides to organise the data and to load it
Ordinary Least Squares example¶
Let's delve first into an OLS example.
Info
You can follow this example using this [notebook](https://github.com/fablabbcn/smartcitizen-iscape-data/blob/master/examples/model_creation.ipynb)
from src.models.model import model_wrapper
# Input model description
model_description_ols = {"model_name": "OLS_UCD",
"model_type": "OLS",
"model_target": "ALPHASENSE",
"data": {"train": {"2019-03_EXT_UCD_URBAN_BACKGROUND_API": {"devices": ["5262"],
"reference_device": "CITY_COUNCIL"}},
"test": {"2019-03_EXT_UCD_URBAN_BACKGROUND_API": {"devices": ["5565"],
"reference_device": "CITY_COUNCIL"}},
"features": {"REF": "NO2_CONV",
"A": "GB_2W",
"B": "GB_2A",
"C": "HUM"},
"data_options": {"frequency": '1Min',
"clean_na": True,
"clean_na_method": "drop",
"min_date": None,
"frequency": "1Min",
"max_date": '2019-01-15'},
},
"hyperparameters": {"ratio_train": 0.75},
"model_options": {"session_active_model": True,
"show_plots": True,
"export_model": False,
"export_model_file": False,
"extract_metrics": True}
}
More info
Check the guide on batch analysis for a definition of each parameter.
We have to keep at least the key REF within the "features", but the rest can be renamed at will. We can also input whichever formula_expression for the model regression in the following format:
"expression" : 'REF ~ A + np.log(B)'
Which converts to:
We can also define the ratio between the train and test dataset and the minimum dates to use within the datasets (globally):
min_date = '2018-08-31 00:00:00'
max_date = '2018-09-06 00:00:00'
# Important that this is a float, don't forget the .
"hyperparameters": {"ratio_train": 0.75}
If we run this cell, we will perform model calibration, with the following output:
OLS Regression Results
==============================================================================
Dep. Variable: REF R-squared: 0.676
Model: OLS Adj. R-squared: 0.673
Method: Least Squares F-statistic: 197.5
Date: Thu, 06 Sep 2018 Prob (F-statistic): 1.87e-135
Time: 12:25:17 Log-Likelihood: 1142.9
No. Observations: 575 AIC: -2272.
Df Residuals: 568 BIC: -2241.
Df Model: 6
Covariance Type: nonrobust
==================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------
Intercept -3.7042 0.406 -9.133 0.000 -4.501 -2.908
A 0.0011 0.000 2.953 0.003 0.000 0.002
np.log(B) -3.863e-05 7.03e-06 -5.496 0.000 -5.24e-05 -2.48e-05
==============================================================================
Omnibus: 7.316 Durbin-Watson: 0.026
Prob(Omnibus): 0.026 Jarque-Bera (JB): 10.245
Skew: -0.076 Prob(JB): 0.00596
Kurtosis: 3.636 Cond. No. 4.29e+05
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 4.29e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
This output brings a lot of information. First, we find what the dependent variable is, in our case always 'REF'. The type of model used and some general information is shown below that.
More statistically important information is found in the rest of the output. Some key data:
- R-squared and adjusted R-squared: this is our classic correlation coefficient or R2. The adjusted one aims to correct the model overfitting by the inclusion of too many variables, and for that introduces a penalty on the number of variables included
- Below, we can find a summary of the model coefficients applied to all the variables and the P>|t| term, which indicates the significance of the term introduced in the model
- Model quality diagnostics are also indicated. Kurtosis and skewness are metrics for determining the distribution of the residuals. They indicate how the residuals of the model resemble a normal distribution. Below, we will review more on diagnosis plots. The Jarque Bera test indicates if the residuals are normally distributed (the null hypothesis is a joint hypothesis of the skewness being zero and the excess kurtosis being zero), and a value of zero indicates that the data is normally distributed. If the Jarque Bera test is valid (in the case above it isn't), the Durbin Watson is applicable in order to check for autocorrelation of the residuals (meaning that the residuals of our model are related among themselves and that we haven't captured some characteristics of our data with the tested model).
Finally, there is a warning at the bottom indicating that the condition number is large. It suggests we might have multicollinearity problems in our model, which means that some of the independent variables might be correlated among themselves and that they are probably not necessary.
Our function also depicts the results in a graphical way for us to see the model itself. It will show the training and test datasets (as Reference Train and Reference Test respectively), and the prediction results. The mean and absolute confidence intervals for 95% confidence are also shown:

Now we can look at some other model quality plots. If we run the cell below, we will obtain an adaptation of the summary plots from R:
from linear_regression_utils import modelRplots
%matplotlib inline
modelRplots(model, dataTrain, dataTest)
Let's review the output step by step:
- Residual vs Fitted and Scale Location plot: these plots represents the model heteroscedasticity , which is a representation of the residuals versus the fitted values. This plot is helpful to check if the errors are distributed homogeneously and that we are not penalising high, low, or other values. There is also a red line which represents the average trend of this distribution which, we want it to be horizontal. For more information visit here and here. Clearly, in this model we are missing something:
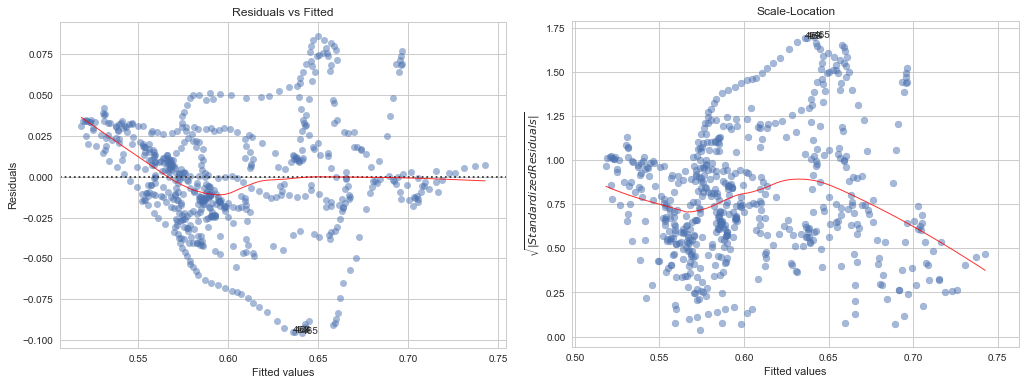
-
Normal QQ: the qq-plot is a representation of the kurtosis and skewness of the residuals distribution. If the data were well described by a normal distribution, the values should be about the same, i.e.: on the diagonal (red line). For example, in our case the model presents a deviation on both tails, indicating skewness. In general, a simple rubric to interpret a qq-plot is that if a given tail twists off counterclockwise from the reference line, there is more data in that tail of your distribution than in a theoretical normal, and if a tail twists off clockwise there is less data in that tail of your distribution than in a theoretical normal. In other words:
- if both tails twist counterclockwise we have heavy tails (leptokurtosis),
- if both tails twist clockwise, we have light tails (platykurtosis),
- if the right tail twists counterclockwise and the left tail twists clockwise, we have right skew
- if the left tail twists counterclockwise and the right tail twists clockwise, we have left skew

-
Residuals vs Leverage: this plot is probably the most complex of them all. It shows how much leverage one single point has on the whole regression. It can be interpreted as how the average line that passes through all the data (that we are calculating with the OLS) can be modified by 'far' points in the distribution, for example, outliers. This leverage can be seen as how much a single point is able to pull down or up the average line. One way to think about whether or not the results are driven by a given data point is to calculate how far the predicted values for your data would move if your model were fit without the data point in question. This calculated total distance is called Cook's distance. We can have four cases (more information from source, here)
- everything is fine (the best)
- high-leverage, but low-standardized residual point
- low-leverage, but high-standardized residual point
- high-leverage, high-standardized residual point (the worst)

In this case, we see that our model has some points with higher leverage but low residuals (probably not too bad) and that the higher residuals are found with low leverage, which means that our model is safe to outliers. If we run this function without the filtering, some outliers will be present and the plot turns into:

Finally, we can export our model and generate some metrics to evaluate the results.
Machine learning example¶
Machine learning algorithms promise a better representation of the sensor's data, being able to learn robust non-linear models and sequential dependencies. For that reason, we have implemented toolset based on keras with Tensorflow backend, in order to train sequential models 3.
model_description_rf = {"model_name": "RF_UCD",
"model_type": "RF",
"model_target": "ALPHASENSE",
"data": {"train": {"2019-03_EXT_UCD_URBAN_BACKGROUND_API": {"devices": ["5262"],
"reference_device": "CITY_COUNCIL"}},
"test": {"2019-03_EXT_UCD_URBAN_BACKGROUND_API": {"devices": ["5565"],
"reference_device": "CITY_COUNCIL"}},
"features": {"REF": "NO2_CONV",
"A": "GB_2W",
"B": "GB_2A",
"C": "HUM"},
"data_options": {"target_raster": '1Min',
"clean_na": True,
"clean_na_method": "drop",
"min_date": None,
"frequency": "1Min",
"max_date": '2019-01-15'},
},
"hyperparameters": {"ratio_train": 0.75,
"min_samples_leaf": 2,
"max_features": None,
"n_estimators": 100,
"shuffle_split": True},
"model_options": {"session_active_model": True,
"show_plots": True,
"export_model": False,
"export_model_file": False,
"extract_metrics": True}
}
Output:
Using TensorFlow backend.
...
Beginning Model RF_UCD
Model type RF
Preparing dataframe model for test 2019-03_EXT_UCD_URBAN_BACKGROUND_API
Data combined successfully
Creating models session in recordings
Dataframe model generated successfully
Training Model RF_UCD...
Training done
Variable: HUM_5262 Importance: 0.4
Variable: GB_2W_5262 Importance: 0.31
Variable: GB_2A_5262 Importance: 0.3
Calculating Metrics...
Metrics Summary:
Metric Train Test
avg_ref 16.648 15.861
avg_est 16.666 16.000
sig_ref 11.438 10.584
sig_est 9.493 9.404
bias 0.019 0.139
normalised_bias 0.002 0.013
sigma_norm 0.830 0.888
sign_sigma -1.000 -1.000
rsquared 0.799 0.879
RMSD 5.124 3.677
RMSD_norm_unb 0.453 0.351
No specifics for RF type
Preparing devices from prediction
Channel 5262_RF_UCD prediction finished
This will also output some nice plots for visually checking our model performance:

And some extras about variable importance:

Model comparison¶
Here is a visual comparison of both models:

It is very difficult though, to know which one is performing better. Let's then evaluate and compare our models. In order to evaluate it's metrics, we will be using the following principles12:
Info
In all of the expressions below, the letter m indicates the model field, r indicates the reference field. Overbar is average and \sigma is the standard deviation.
Linear correlation Coefficient A measure of the agreement between two signals:
The correlation coefficient is bounded by the range -1 \le R \le 1. However, it is difficult to discern information about the differences in amplitude between two signals from R alone.
Normalized standard deviation A measure of the differences in amplitude between two signals:
unbiased Root-Mean-Square Difference A measure of how close the modelled points fall to teach other:
Potential Bias Difference between the means of two fields: $$ B = \overline m - \overline r $$ Total RMSD A measure of the average magnitude of difference: $$ RMSD = \Bigl( {1 \over N} \sum_{n=1}^N (m_n - r_n)^2 \Bigr)^{0.5} $$
In other words, the unbiased RMSD (RMSD') is equal to the total RMSD if there is no bias between the model and the reference fields (i.e. B = 0). The relationship between both reads:
In contrast, the unbiased RMSD may be conceptualized as an overall measure of the agreement between the aplitude (\sigma) and phase (\phi) of two temporal patterns. For this reason, the correlation coefficient (R), normalised standard deviation (\sigma*), and unbiased RMSD are all referred to as patern statistics, related to one another by:
Normalized and unbiased RMSD If we recast in standard deviation normalized units (indicated by the asterisk) it becomes:
NB: the minimum of this function occurrs when \sigma* = R.
Normalized bias Gives information about the mean difference but normalized by the \sigma* $$ B* = {\overline m - \overline r \over \sigma_r} $$
Target diagrams The target diagram is a plot that provides summary information about the pattern statistics as well as the bias thus yielding an overview of their respective contributions to the total RMSD. In a simple Cartesian coordinate system, the unbiased RMSD may serve as the X-axis and the bias may serve as the Y-axis. The distance between the origin and the model versus observation statistics (any point, s, within the X,Y Cartesian space) is then equal to the total RMSD. If all is normalized by the \sigma_r, the distance from the origin is again the standard deviation normalized total RMSD:1
The resulting target diagram then provides information about:
- whether the \sigma_m is larger or smaller thann the \sigma_r
- whether there is a positive or negative bias

Image Source: Jolliff et al. 1
Any point greater than RMSD*=1 is to be considered a poor performer since it doesn't offer improvement over the time series average.
Interestingly, the target diagram has no information about the correlation coefficient R, but some can be inferred, knowing that all the points within the RMSD* <1 are positively correlated (R>0), although, in 1 it is shown that a circle marker with radius M_{R1}, means that all the points between that marker and the origin have a R coefficient larger than R1, where:
Results¶
Let's now compare both models with the target diagram:
from src.visualization.visualization import targetDiagram
%matplotlib inline
models = dict()
group = 0
for model in [ols_model, rf_model]:
for dataset in ['train', 'validation']:
if dataset in model.metrics.keys():
models[model.name + '_' + dataset] = model.metrics[dataset]
models[model.name + '_' + dataset]['group'] = group
targetDiagram(models, True, 'seaborn-talk')
Output:

Here, every point that falls inside the yellow circle, will have an R2 over 0.7, and so will be the red and green for R2 over 0.5 and 0.9 respectively. We see that only one of our models performs well in that sense, which is the training dataset of the OLS. However, this dataset performs pretty badly in the test dataset, being the LSTM options much better. This target diagram offers information about how the hyperparameters affect our networks. For instance, increasing the training epochs from 100 to 200 does not affect greatly on model performance, but the effect of filtering the data beforehand to reduce the noise shows a much better model performance in both, training and test dataframe.
Export the models¶
Let's now assume that we are happy with our models. We can now export them:
ols_model.export('directory')
rf_model.export('directory')
Output:
Saving metrics
Saving hyperparameters
Saving features
Model included in summary
And in our directory:
➜ models ls -l
RF_UCD_features.sav
RF_UCD_hyperparameters.sav
RF_UCD_metrics.sav
Save the model file
If you want to save the model file into the disk, change the option "export_model": False, to True! Be careful though, it can take quite a lot of space. If you just want to keep the model to test in the current session, it is best to just use "session_active_model": True,.